[CVPR25] Dynamic Motion Blending for Versatile Motion Editing
Abstract
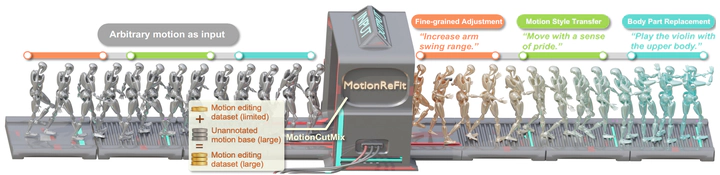
Text-guided motion editing enables high-level semantic control and iterative modifications beyond traditional keyframe animation. Existing methods rely on limited pre-collected training triplets, which severely hinders their versatility in diverse editing scenarios. We introduce MotionCutMix, an online data augmentation technique that dynamically generates training triplets by blending body part motions based on input text. While MotionCutMix effectively expands the training distribution, the compositional nature introduces increased randomness and potential body part incoordination. To model such a rich distribution, we present MotionReFit, an auto-regressive diffusion model with a motion coordinator. The auto-regressive architecture facilitates learning by decomposing long sequences, while the motion coordinator mitigates the artifacts of motion composition. Our method handles both spatial and temporal motion edits directly from high-level human instructions, without relying on additional specifications or Large Language Models. Through extensive experiments, we show that MotionReFit achieves state-of-the-art performance in text-guided motion editing.
Nan Jiang
Ph.D. '22
Hongjie Li
Zhi Class '21
My research interests include human-object interaction and scene understanding in 3D computer vision.