[ICRA20] Joint Inference of States, Robot Knowledge, and Human (False-)Beliefs
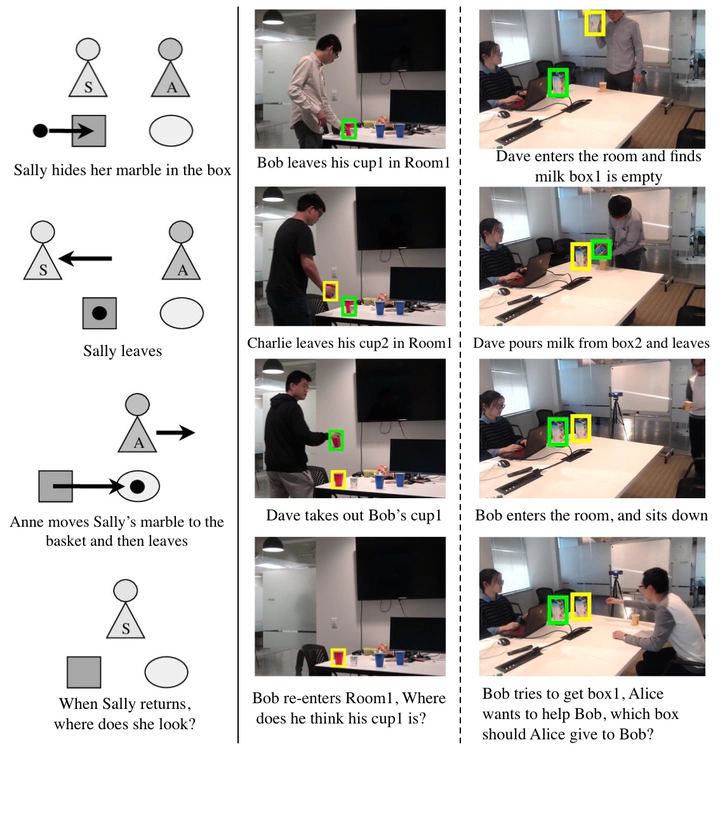 Left: Illustration of the classic Sally-Anne test. Middle and Right: Two different types of false-belief scenarios in our dataset: belief test and helping test.
Left: Illustration of the classic Sally-Anne test. Middle and Right: Two different types of false-belief scenarios in our dataset: belief test and helping test.Abstract
Aiming to understand how human (false-)belief—a core socio-cognitive ability—would affect human interactions with robots, this paper proposes to adopt a graphical model to unify the representation of object states, robot knowledge, and human (false-)beliefs. Specifically, a parse graph (PG) is learned from a single-view spatiotemporal parsing by aggregating various object states along the time; such a learned representation is accumulated as the robot’s knowledge. An inference algorithm is derived to fuse individual PG from all robots across multi-views into a joint PG, which affords more effective reasoning and inference capability to overcome the errors originated from a single view. In the experiments, through the joint inference over PGs, the system correctly recognizes human (false-)belief in various settings and achieves better cross-view accuracy on a challenging small object tracking dataset.