[ICCV21] Spatio-temporal Self-Supervised Representation Learning for 3D Point Clouds
Abstract
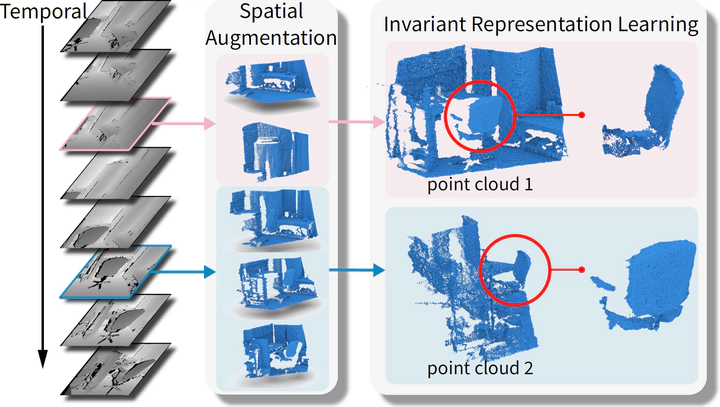
To date, various 3D scene understanding tasks still lack practical and generalizable pre-trained models, primarily due to the intricate nature of 3D scene understanding tasks and their immense variations introduced by camera views, lighting, occlusions, etc. In this paper, we tackle this challenge by introducing a spatio-temporal representation learning (STRL) framework, capable of learning from unlabeled 3D point clouds in a self-supervised fashion. Inspired by how infants learn from visual data in the wild, we explore the rich spatio-temporal cues derived from the 3D data. Specifically, STRL takes two temporally-correlated frames from a 3D point cloud sequence as the input, transforms it with the spatial data augmentation, and learns the invariant representation self-supervisedly. To corroborate the efficacy of STRL, we conduct extensive experiments on three types (synthetic, indoor, and outdoor) of datasets. Experimental results demonstrate that, compared with supervised learning methods, the learned self-supervised representation facilitates various models to attain comparable or even better performances while capable of generalizing pre-trained models to downstream tasks, including 3D shape classification, 3D object detection, and 3D semantic segmentation. Moreover, the spatio-temporal contextual cues embedded in 3D point clouds significantly improve the learned representations.