[IJCV22] Scene Reconstruction with Functional Objects for Robot Autonomy
Abstract
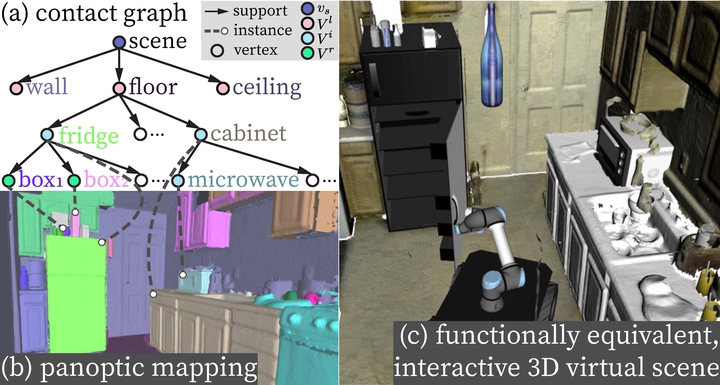
In this paper, we rethink the problem of scene reconstruction from an embodied agent’s perspective: While the classic view focuses on the reconstruction accuracy, our new perspective emphasizes the underlying functions and constraints of the reconstructed scenes that provide actionable information for simulating interactions with agents. Here, we address this challenging problem by reconstructing a functionally equivalent and interactive scene from RGB-D data streams, where the objects within are segmented by a dedicated 3D volumetric panoptic mapping module and subsequently replaced by part-based articulated CAD models to afford finer-grained robot interactions. The object functionality and contextual relations are further organized by a graph-based scene representation that can be readily incorporated into robots’ action specifications and task definition, facilitating their long-term task and motion planning in the scenes. In the experiments, we demonstrate that (i) our panoptic mapping module outperforms previous state-of-the-art methods in recognizing and segmenting scene entities, (ii) the geometric and physical reasoning procedure matches, aligns, and replaces object meshes with best-fitted CAD models, and (iii) the reconstructed functionally equivalent and interactive scenes are physically plausible and naturally afford actionable interactions; without any manual labeling, they are seamlessly imported to ROS-based robot simulators and VR environments for simulating complex robot interactions.
