[CVPR26] Scalable Trajectory Generation for Whole-Body Mobile Manipulation
Abstract
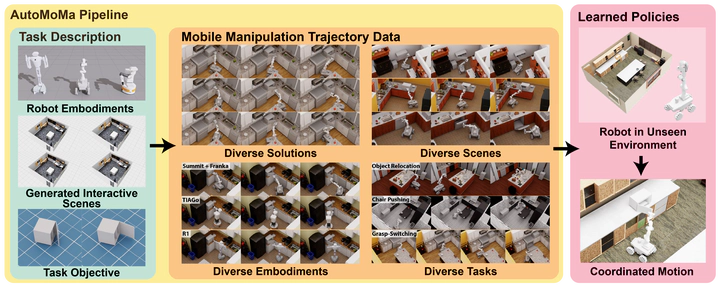
Robots deployed in unstructured environments must coordinate whole-body motion—simultaneously moving a mobile base and arm—to interact with the physical world. This coupled mobility and dexterity yields a state space that grows combinatorially with scene and object diversity, demanding datasets far larger than those sufficient for fixed-base manipulation. Yet existing acquisition methods, including teleoperation and planning, are either labor-intensive or computationally prohibitive at scale. The core bottleneck is the lack of a scalable pipeline for generating large-scale, physically valid, coordinated trajectory data across diverse embodiments and environments. Here we introduce AutoMoMa, a GPU-accelerated framework that unifies AKR modeling, which consolidates base, arm, and object kinematics into a single chain, with parallelized trajectory optimization. AutoMoMa achieves 5,000 episodes per GPU-hour, producing a dataset of over 500k physically valid trajectories spanning 330 scenes, diverse articulated objects, and multiple robot embodiments. Prior datasets were forced to compromise on scale, diversity, or kinematic fidelity; AutoMoMa addresses all three simultaneously. Training downstream imitation learning policies further reveals that even a single articulated-object task requires tens of thousands of demonstrations for state-of-the-art methods to reach around 80% success, confirming that data scarcity—not algorithmic limitations—has been the binding constraint. AutoMoMa thus bridges high-performance planning and reliable IL-based control, providing the infrastructure previously missing for coordinated mobile manipulation research. By making large-scale, kinematically valid training data practical, AutoMoMa showcases generalizable whole-body robot policies capable of operating in the diverse, unstructured settings of the real world.
Xinhai Chang
Undergrad '22
My research interests cover robot manipulation, task and motion planning, and 3D scene reconstruction.